XML Format¶
This section describes the structure of the XML file used for describing an experiment (see Survey Tab for how to upload the XML file to Crowdsourcr).
For instructional examples, load and view (in labeled order) the files located in the examples folder.
You can hand-draft XML files or create them programmatically. The __surveyCreation folder inside the examples folder has an example of how to create a
survey XML file programmatically. However, it is sometimes easier to hand-craft at least parts of a survey in order interactively test the functionality. For example,
the survey iterator_example.xml is a hand-crafted survey which was later incorporated into a Python script that creates the full survey.
The main structure of a survey XML file is as follows:
<xml>
<modules>
... module definitions ...
</modules>
<tasks>
... task definitions ...
</tasks>
<hits>
... hit definitions ...
</hits>
<sets>
... set definitions ...
</sets>
<documents>
... document definitions ...
</documents>
</xml>
The documents and sets sections are optional if it is empty, otherwise the
first three are required.
Modules¶
A module has an internal name, a visible header, and a list of questions:
<module>
<name>module_name</name>
<header>Visible Module Header</header>
<questions>
... question definitions ...
</questions>
</module>
Iterators¶
Sometimes you design surveys with almost identical modules. Consider the survey iterator_example.xml. In this survey, respondents are asked to answer questions on
three sentences. Each module corresponds to one sentence and contains otherwise exactly the same questions.
One solution would be to simply replicate the module three times. However, this is error-prone when hand-crafting a survey. Crowdsourcr provides an interator tag as follows:
<module>
<iterator>
<dimensions>
<dimension>
<name>SENTENCE</name>
<instances>
<instance>
<kvpairs>
<kvpair>
<key>ID</key>
<value>1</value>
</kvpair>
</kvpairs>
</instance>
<instance>
<kvpairs>
<kvpair>
<key>ID</key>
<value>2</value>
</kvpair>
</kvpairs>
</instance>
<instance>
<kvpairs>
<kvpair>
<key>ID</key>
<value>3</value>
</kvpair>
</kvpairs>
</instance>
<instance>
<kvpairs>
<kvpair>
<key>ID</key>
<value>4</value>
</kvpair>
</kvpairs>
</instance>
</instances>
</dimension>
</dimensions>
</iterator>
<name>s{SENTENCE:ID}</name>
<header>Sentence {SENTENCE:ID}</header>
<contentUpdate>highlight;s{SENTENCE:ID}</contentUpdate>
(..)
</module>
The iterator defines an interator dimension called SENTENCE. In this example there is a single dimension but there could be several dimensions (for example,
a secondary dimension could be political slant if you want to create a version of the module that is aimed to ask about republican/democratic slant of a sentence).
The iterator then iterates over instances. In this example, there are four instances. Each instance defines a set of variable allocations that hold within that
instance. In this example, there is a single variable called ID that can take the values 1 to 4 in the four instances. Crowdsourcr will therefore internally
create 4 modules named s1 to s4.
Questions¶
There are a few types of questions which have been defined. The general format for a question definition is
<question>
<varname>internal_variable_name</varname>
<questiontext>Visible question text</questiontext>
(<helptext>Optional help text</helptext>)
<valuetype>some_value_type</valuetype>
...
</question>
The variable name is for determining how the answer is recorded into the response data. The value type determines how the question is rendered.
Numeric questions¶
A numeric question (value type numeric) displays as a text box
that only accepts a number. An example:

<question>
<varname>age</varname>
<valuetype>numeric</valuetype>
<questiontext>What is your age?</questiontext>
<helptext>This is your age in years.</helptext>
</question>
Text questions¶
A text question (value type text) displays as a text box that
accepts any non-empty textual content. An example:
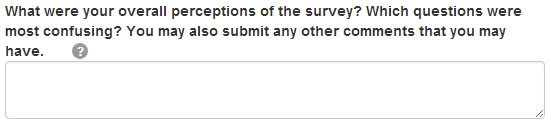
<question>
<varname>thoughts</varname>
<valuetype>text</valuetype>
<questiontext>What were your overall perceptions of the survey?
Which questions were most confusing? You may also submit any
other comments that you may have.</questiontext>
<helptext>We want to better understand the strenghts and weaknesses
of our survey in order to improve it for future workers. Your
answer to this question will not influence your
payment.</helptext>
</question>
There is also an approximate text question (value type approximatetext). This displays the same way as a normal text question.
However, for bonus calculations, two submissions are considered to match if their Jaccard similarity exceeds 75 percent.
Categorical questions¶
A categorical question (value type categorical) displays as a set
of radio buttons that accepts exactly one response. An example:

<question>
<varname>married</varname>
<questiontext>Are you married?</questiontext>
<helptext>Please answer metaphorically.</helptext>
<valuetype>categorical</valuetype>
<content>
<categories>
<category>
<text>Yes</text>
<value>yes</value>
</category>
<category>
<text>No</text>
<value>no</value>
</category>
</categories>
</content>
</question>
The text element holds what is shown to the worker, and the
value element holds what is recorded to the database for that
categorical response.
Each category also has an optional parameter aprioripermissable which can be set to true or false (if missing it is set to false).
<question>
<varname>favoritecolor</varname>
<questiontext>Which color do you like better?</questiontext>
<valuetype>categorical</valuetype>
<content>
<categories>
<category>
<text>Red</text>
<value>red</value>
<aprioripermissable>true</aprioripermissable>
</category>
<category>
<text>Blue</text>
<value>blue</value>
<aprioripermissable>true</aprioripermissable>
</category>
</categories>
</content>
</question>
This parameter matters for bonus calculations: if there is any conditional branching that omits certain tasks or questions
that involves any condition with aprioripermissable variables then the share of agreement for bonus purposes is based
only on the number of workers who ended up in this branch and not on the number of workers who could have seen this question.
This is used, for example, in the elaborate_conditional_tasks.xml survey. In that survey, workers are first asked
for their favorite color (red or blue) and both colors are apriori permissable (meaning there is no right or wrong answer).
Depending on the color choice, the survey then asks if this light is in the low or high-frequency part of the spectrum (which involves two conditional tasks).
The frequency questions are incentivized with bonus points.
Since the color choices are marked as apriori permissable the bonus points for the red frequency question are only calculated
relative to the majority answer among people who chose red. For example, if 4 people complete the survey correctly and
two of them have favorite color red'' and two have ``blue then the agreement level will be 100 percent. Otherwise, the agreement
level would be only 50 percent since only 2 people answered the frequency question identically (out of a possible 4 who
could have answered this question).
Nested categorical questions¶
For some questions, it is better to show categorical options
hierarchically. The syntax is exactly the same for categorical
questions, except that the text elements hold |-separated
options. The responses will be shown in a tree-like fashion. An example:
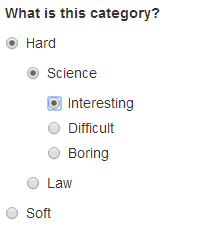
<question>
<varname>level_category</varname>
<valuetype>categorical</valuetype>
<questiontext>What is this category?</questiontext>
<content>
<categories>
<category>
<text>Hard|Science|Interesting</text>
<value>hard_science_interesting</value>
</category>
<category>
<text>Hard|Law</text>
<value>hard_law</value>
</category>
<category>
<text>Hard|Science|Difficult</text>
<value>hard_science_difficult</value>
</category>
<category>
<text>Hard|Science|Boring</text>
<value>hard_science_boring</value>
</category>
<category>
<text>Soft|Animals</text>
<value>soft</value>
</category>
</categories>
</content>
</question>
It is possible to have optional specificity. For example, if we added
a category with text Soft|Animals|Teddy Bear to the above
definition, then a user could answer either Soft|Animals or the
sub-category Soft|Animals|Teddy Bear.
Scale questions¶
For some categorical questions, the options are along a scale that is
best presented horizontally. This is specified using the
horizontal layout in the options element for the question. An
example:

<question>
<varname>bias</varname>
<valuetype>categorical</valuetype>
<questiontext>How biased is this?</questiontext>
<options>
<layout>horizontal</layout>
<lowLabel>Conservative</lowLabel>
<highLabel>Liberal</highLabel>
<outsideCategories>N/A</outsideCategories>
<outsideCategories>Unsure</outsideCategories>
</options>
<content>
<categories>
<category>
<text>1</text>
<value>1</value>
</category>
<category>
<text>2</text>
<value>2</value>
</category>
<category>
<text>3</text>
<value>3</value>
</category>
<category>
<text>4</text>
<value>4</value>
</category>
<category>
<text>5</text>
<value>5</value>
</category>
<category>
<text>6</text>
<value>6</value>
</category>
</categories>
</content>
</question>
Image upload questions¶
You can upload images (up to 16MB per question).
<question>
<varname>nyt_logo</varname>
<questiontext>Please upload a nytlogo</questiontext>
<valuetype>imageupload</valuetype>
</question>
The variable will only store an image hash. The raw BASE64-encoded image will be stored under a second variable with suffix _raw
added. For example, nyt_logo will become ny_logo_raw while nyt_logo will hold the hash. The image hash allows you to
compare the similarity through simple differences. A threshold difference of 20 is internally used for defining two images
as identical for bonus calculations.
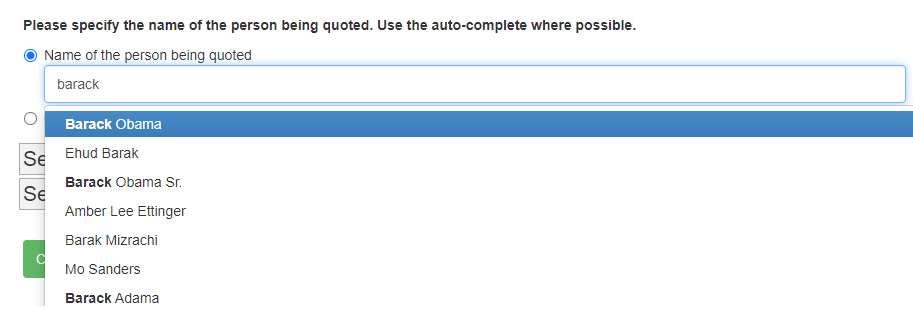
Autocomplete questions¶
You can create text questions with auto-complete.
<question>
<varname>sentence_quote_speaker_specific_person</varname>
<questiontext>Please specify the name of the person. Use the auto-complete where possible.</questiontext>
<condition>
<![CDATA[
((sentence==directquote)|(sentence==indirectquote)|(sentence==paraphrasequote))&({SPEAKER:CONDITION})
]]>
</condition>
<valuetype>autocomplete</valuetype>
<options>
<sureLabel>Name of the {SPEAKER:LONG1}</sureLabel>
<sureLabelPlaceholder>Specify name of {SPEAKER:LONG2}</sureLabelPlaceholder>
<unsureLabel>Quoted {SPEAKER:LONG3} cannot be identified</unsureLabel>
<autoCompleteUrl>https://www.autocomplete.econlabs.org/api/auto/getperson</autoCompleteUrl>
</options>
</question>
Autocomplete questions are identical to standard text questions except that you define a link to an autocomplete service (by url). This service has to accept GET requests
with query parameter q and value equal to the partial entry in the textbox. The result has to be delivered as a JSON array.
Iterators¶
Sometimes you design surveys with almost identical questions. This happens often when you have conditional questions.
Consider the survey iterator_example.xml. In this survey, respondents are asked to answer questions on sentences in articles.
In a previous question they were asked whether the sentence is in the author’s own words or quoting someone
else (directly or indirectly). In this question the respondent specifies whether the author’s own words/the quote are expressing a fact or an opinion.
We want to create different question wordings depending on whether the respondent previously classified the sentence as author’s own words or a quote.
<question>
<iterator>
<dimensions>
<dimension>
<name>SENTENCE</name>
<instances>
<instance>
<kvpairs>
<kvpair>
<key>SHORT</key>
<value>ownwords</value>
</kvpair>
<kvpair>
<key>CONDITION</key>
<value>sentence==ownwords</value>
</kvpair>
<kvpair>
<key>LONG</key>
<value>author</value>
</kvpair>
</kvpairs>
</instance>
<instance>
<kvpairs>
<kvpair>
<key>SHORT</key>
<value>quote</value>
</kvpair>
<kvpair>
<key>CONDITION</key>
<value><![CDATA[
((sentence==directquote)|(sentence==indirectquote)|(sentence==paraphrasequote))&(exists{sentence_quote_speaker_specific_*})
]]>
</value>
</kvpair>
<kvpair>
<key>LONG</key>
<value>quoted person or organization</value>
</kvpair>
</kvpairs>
</instance>
</instances>
</dimension>
</dimensions>
</iterator>
<varname>sentence_{SENTENCE:SHORT}_contenttype</varname>
<questiontext>The {SENTENCE:LONG} is ... </questiontext>
<condition>
<![CDATA[
{SENTENCE:CONDITION}
]]>
</condition>
<valuetype>categorical</valuetype>
<content>
<categories>
<category>
<text>... making a factual statement. Such a statement can be proven to be true or false through objective evidence.|Supporting evidence that proves the statement true or false already exists.</text>
<value>fact_existing</value>
</category>
<category>
<text>... making a factual statement. Such a statement can be proven to be true or false through objective evidence.|Supporting evidence that will prove the statement true or false will likely exist in the future (for example for a new scientific theory).</text>
<value>fact_pending</value>
</category>
<category>
<text>... stating an opinion|an emotion or an attitude</text>
<value>opinion_emotion</value>
</category>
<category>
<text>... stating an opinion|a value judgment</text>
<value>opinion_judgment</value>
</category>
<category>
<text>... stating an opinion|an unprovable belief (for example a statement such as "Destiny guides our lives.")</text>
<value>opinion_unprovable</value>
</category>
<category>
<text>... neither a factual statement nor an opinion.</text>
<value>neither</value>
</category>
</categories>
</content>
</question>
The iterator defines an interator dimension called SENTENCE. In this example there is a single dimension but there could be several dimensions (just like for modules).
The iterator then iterates over instances. In this example, there are two instances: one for ownwords'' and one for ``quote. Each instance defines a set of variable
allocations that hold within that instance. In this example, there are three variables called SHORT, LONG and CONDITION that take the appropriate values for
each instance. Crowdsourcr will therefore internally create 2 questions named sentence_ownwords and sentence_quote.
Tasks¶
Each task consists of a document that is shown on the left screen and a set of modules that are shown on the right.
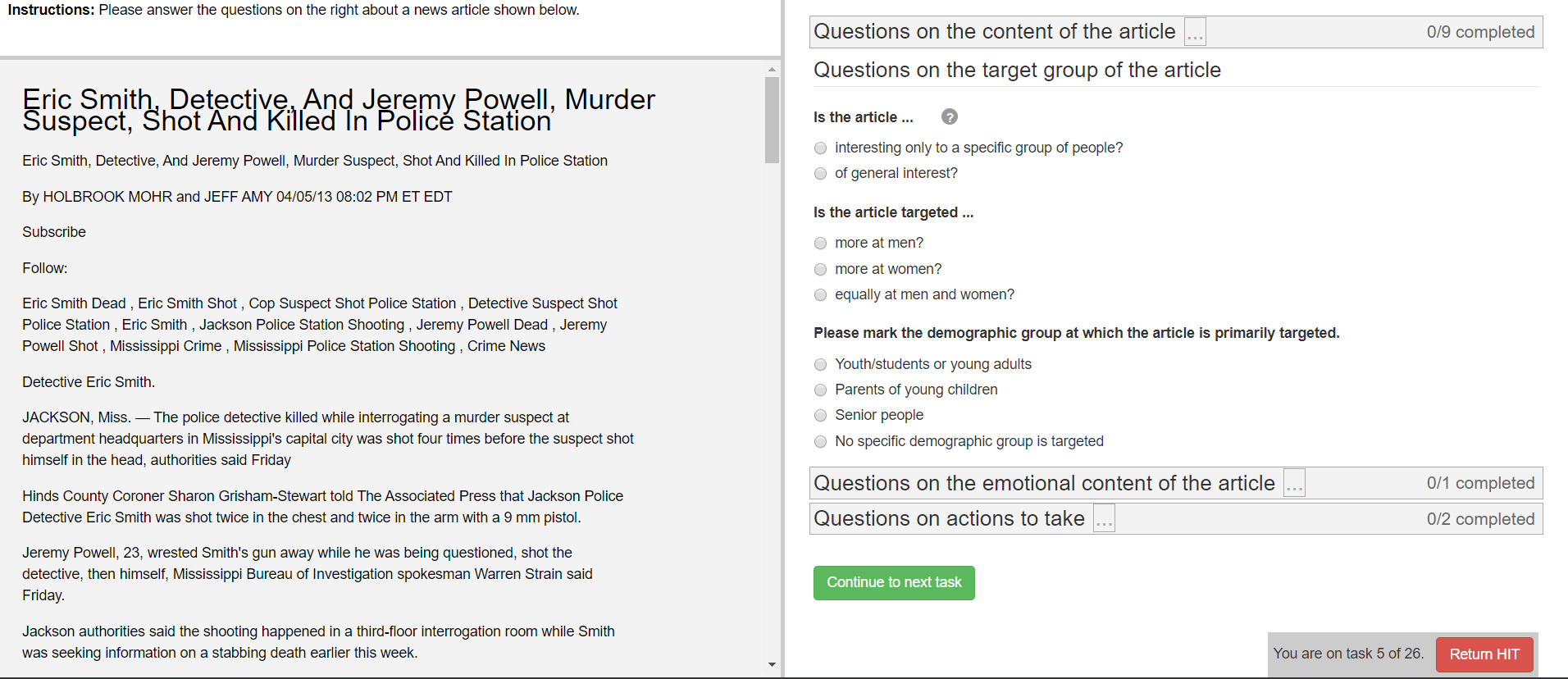
The sample XML file simple_question_conditional_hit.xml has the following three tasks:
<tasks>
<task>
<content>screening.html</content>
<taskid>1</taskid>
<modules>screening</modules>
</task>
<task>
<content>spelling.html</content>
<taskid>2</taskid>
<modules>spelling</modules>
</task>
<task>
<content>demographics.html</content>
<taskid>3</taskid>
<modules>demographics</modules>
</task>
</tasks>
In this example, every task has just one associated module. The complex_modules.xml survey shows an example where tasks have several modules. This XML file generates the screenshot above.
The content value refers to a document that is defined under documents:
<documents>
<document>
<name>screening.html</name>
<content><![CDATA[
<p>On this page we screen you.</p>
]]></content>
</document>
<document>
<name>spelling.html</name>
<content><![CDATA[
<p>Please answer these questions.</p>
]]></content>
</document>
<document>
<name>demographics.html</name>
<content><![CDATA[
<p>On this page we ask questions about yourself.</p>
]]></content>
</document>
</documents>
Any HTML content can be provided under the content property (you can even use it to load external images through <img src="http://my_other_domain/my_image.png">) but you need to encapsulate your HTML in a CDATA tag in order to produce valid XML.
The complex_modules.xml survey provides an example of very rich content panels.
Dynamic content¶
You can make the content change dynamically when switching between modules within a task.
The sample XML file color_coding_test.xml shows an example where the names of different political candidates are highlighted depending
on the module.
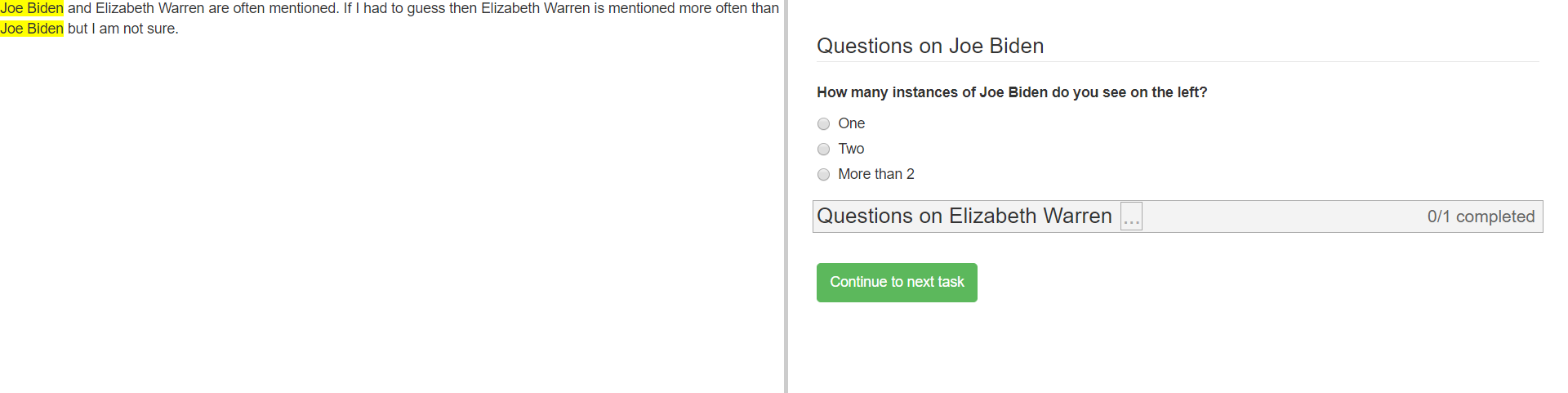
Dynamic content can be included by adding the contentUpdate tag as shown below:
<module>
<header>Questions on Joe Biden</header>
<contentUpdate>highlight;joebiden</contentUpdate>
<name>joebiden</name>
<questions>
<question>
<varname>joebiden</varname>
<questiontext>How many instances of Joe Biden do you see on the left?</questiontext>
<valuetype>categorical</valuetype>
<content>
<categories>
<category>
<text>One</text>
<value>1</value>
</category>
<category>
<text>Two</text>
<value>2</value>
</category>
<category>
<text>More than 2</text>
<value>2+</value>
</category>
</categories>
</content>
</question>
</questions>
</module>
The tag consists of two strings separated by semi-colon. highlight indicates that the corresponding Javascript function should
be called when the user switches to this module with value joebiden.
The content HTML code looks as follows:
<documents>
<document>
<name>names.html</name>
<content><![CDATA[
<style>
.yellow {
background-color: yellow
}
.green {
background-color: #8FBC8F
}
</style>
<script>
var highlight=function(name){
var tags=document.getElementsByTagName("SPAN");
for (let tag of tags) {
if (tag.getAttribute("nameMarker")==name){
if (name=="joebiden"){
tag.className="yellow";
}
if (name=="elizabethwarren"){
tag.className="green";
}
}
else{
tag.className="";
}
}
}
</script>
<p><span nameMarker="joebiden">Joe Biden</span> and <span nameMarker="elizabethwarren">Elizabeth Warren</span> are often mentioned. If I had to guess
then <span nameMarker="elizabethwarren">Elizabeth Warren</span> is mentioned more often than <span nameMarker="joebiden">Joe Biden</span> but I am not sure.
]]></content>
</document>
</documents>
cHits¶
A cHIT is a collection of tasks. This is what the Turk worker will see when clicking the link in the Amazon interface. Your cHIT will have as many pages as there are tasks. simple_question_conditional_hit.xml defines 3 cHITs each consisting of three tasks.
<hits>
<hit>
<hitid>1</hitid>
<tasks>1 2 3</tasks>
<taskconditions>
<taskcondition>
<taskid>2</taskid>
<condition>
<![CDATA[
1*screening*smart+1*screening*kidding+1*screening*sum10+1*screening*sum15+1*screening*biggerthan>=4
]]>
</condition>
</taskcondition>
<taskcondition>
<taskid>3</taskid>
<condition>
<![CDATA[
notinset{$workerid,excludedemographics}
]]>
</condition>
</taskcondition>
</taskconditions>
</hit>
<hit>
<hitid>2</hitid>
<tasks>1 2 3</tasks>
</hit>
<hit>
<hitid>3</hitid>
<tasks>1 2 3</tasks>
</hit>
</hits>
In this example, the three tasks 1 to 3 are assigned to three cHITs. This implies triple data entry which makes workers potentially eligible for a bonus payment (see Bonus ).
Exclusions¶
Each cHIT may specify a set of exclusions, a whitespace separated list of other HIT IDs such that if a worker has completed any of the HITs listed as exclusions she may not complete the cHIT that listed those exclusions. Perhaps an example would be most informative. Consider the following HITs:
<hits>
<hit>
<hitid>1</hitid>
<exclusions>2</exclusions>
<tasks>
1
2
</tasks>
</hit>
<hit>
<hitid>2</hitid>
<tasks>
1
</tasks>
</hit>
</hits>
In this case, a worker who first completes cHIT 2 may not then complete cHIT 1, since cHIT 1 excludes cHIT 2. However, since HIT 2 lists no exclusions, a worker who first completes HIT 1 would then be permitted to complete HIT 2. There is no enforcement that exclusions be symmetric.
Note: a worker who has already submitted an invalid cHIT (a cHIT that did not pass cHIT Validation and Automatic Reassignments) is excluded from all future cHITs.
Data Download¶
When you download data in the administrator’s Survey Tab every question will be coded by task_id, module_name and varname. Example:

Task Conditions¶
You can define task conditions on the HIT level which determine which dynamically determine which particular task the worker will see. Consider the cHIT with hid ID 1 in simple_question_conditional_hit.xml:
<hit>
<hitid>1</hitid>
<tasks>1 2 3</tasks>
<taskconditions>
<taskcondition>
<taskid>2</taskid>
<condition>
<![CDATA[
1*screening*smart+1*screening*kidding+1*screening*sum10+1*screening*sum15+1*screening*biggerthan>=4
]]>
</condition>
</taskcondition>
<taskcondition>
<taskid>3</taskid>
<condition>
<![CDATA[
notinset{$workerid,excludedemographics}
]]>
</condition>
</taskcondition>
</taskconditions>
</hit>
In this cHIT tasks 1 is a screening task, task 2 is the actual worker task we are interested in and task 3 collects demographic data on the worker.
We don’t want the worker to do the worker task (and potentially collect a bonus) if she does badly in the screen task. This is accomplished through the first condition
<condition>
<![CDATA[
1*screening*smart+1*screening*kidding+1*screening*sum10+1*screening*sum15+1*screening*biggerthan>=4
]]>
</condition>
We also do not want the worker to complete the demographic survey if she previously filled it out. This is accomplished through the second condition:
<condition>
<![CDATA[
notinset{$workerid,excludedemographics}
]]>
</condition>
Set conditions rely on sets to be defined in the XML like this:
<sets>
<set>
<name>excludedemographics</name>
<members>mm lilia</members>
</set>
</sets>
A couple of comments on the syntax of the conditions are in order:
You have to refer to variables by using their full path which consists of task id, module name and variable name. Separate the three parts of the full variable name with the ‘*’ character.
Encapsulate the condition in a CDATA tag to ensure valid XML.
- There are 3 types of basic boolean conditions:
- Equality (
==) and inequality (!=) such as1*screening*smart==1. - Arithmetic sums of variables as long as the values are integers (non-integer values will be ignored at runtime). You can apply equality (
==), inequality (!=) and the arithmetic comparisons greater or equal (
>=) and less or equal (<=).
- Arithmetic sums of variables as long as the values are integers (non-integer values will be ignored at runtime). You can apply equality (
The
insetandnotinsetoperators which check whether a variable is contained in a set (in this caseexcludedemographics).$workeridis a special variable which indicates the ID of the worker.
- Equality (
You can concatenate any type of basic boolean condition using the AND operator
&and the OR operator|. You can also use brackets to nest conditions.
The syntax parser will check while uploading the XML that all conditions are valid (except for summation errors due to variables taking non-integer values).
Conditional Questions¶
The display of questions can be made conditional on the answer to other questions by specifying a <condition>:
<question>
<varname>spelling</varname>
<bonus>threshold:50</bonus>
<questiontext>Please indicate which spelling is correct:</questiontext>
<valuetype>categorical</valuetype>
<content>
<categories>
<category>
<text>Rhythm</text>
<value>0</value>
</category>
<category>
<text>Rythm</text>
<value>1</value>
</category>
<category>
<text>Other spelling</text>
<value>other</value>
</category>
</categories>
</content>
</question>
<question>
<varname>spelling_other</varname>
<condition>
<![CDATA[
spelling==other
]]>
</condition>
<bonus>threshold:50</bonus>
<bonuspoints>2</bonuspoints>
<questiontext>Please specify the spelling.</questiontext>
<valuetype>text</valuetype>
</question>
<question>
<varname>letterc</varname>
<questiontext>What does the letter C stand for?</questiontext>
<valuetype>categorical</valuetype>
<content>
<categories>
<category>
<text>C is for cookie</text>
<value>cookie</value>
</category>
<category>
<text>C is for car</text>
<value>car</value>
</category>
</categories>
</content>
</question>
The parser for conditions is the same as for Task Conditions. However, variable definitions are simplified and only use the variable name because conditions only apply within the context of a module.
Bonus¶
Crowdsourcr has an extensive bonus point framework. Bonus points serve two functions:
First of all, they provide a currency to reward extra questions. This is useful when you have a lot of conditional branching and some hits might take longer than others. Second, you can reward accuracy by awarding bonus points for a task depending on the level of agreement of the worker with other workers who completed the same task.
Specifying a bonus¶
Bonuses can be specified on a per-question basis by adding a <bonus>
element to the XML file. If a question has no <bonus> element
then there are 0 bonus points assigned. Each question with the <bonus> element has one bonus point assigned.
This can be changed by adding a <bonuspoints> element. To always assign bonus points regardless of the answers
of other players use <bonus>threshold:0</bonus>.
In the example below, the worker has the option of answering an extra question for which she receives 2 bonus points.
<question>
<varname>article_extra</varname>
<questiontext>Do you want to answer an optional question? You will receive a bonus payment for answering optional questions.</questiontext>
<valuetype>categorical</valuetype>
<content>
<categories>
<category>
<text>Yes</text>
<value>yes</value>
</category>
<category>
<text>No</text>
<value>no</value>
</category>
</categories>
</content>
</question>
<question>
<varname>article_type</varname>
<questiontext>What kind of article is this?</questiontext>
<condition>
<![CDATA[
article_extra==yes
]]>
</condition>
<bonus>threshold:0</bonus>
<bonuspoints>2</bonuspoints>
<valuetype>categorical</valuetype>
<content>
<categories>
<category>
<text>News article</text>
<value>news</value>
</category>
<category>
<text>Editorial</text>
<value>editorial</value>
</category>
<category>
<text>Other</text>
<value>other</value>
</category>
</categories>
</content>
</question>
The actual dollar bonus per worker is calculated as follows: the sum of bonus points on any cHIT is calculated. The maximum
across all these individuals sum is taken. One bonus point is then valued as the bonus amount specified in the admin panel
(see section cHIT Tab) divided by this maximum number of possible points. For example, in the elaborate_conditional_tasks.xml survey
the sum of all bonus points for any cHIT equals 4. If the bonus amount is set at 1 Dollar then a bonus point is worth 25 cents.
Note, that a worker will therefore never earn more than the bonus amount on any single cHIT
specified in the admin panel (although if a worker completes two cHITs then she can earn this amount twice).
Crowdsourcr calculates the sum of bonus points on any cHIT regardless of whether this sum is actually attainable. For
example, the elaborate_conditional_tasks.xml asks you to pick between color red and blue and then asks
a conditional followup question on each response (which is incentivized with two bonus points). The sum of bonus
points on any cHIT is 4 but a worker can only achieve 2 bonus points. Hence, as the survey designer, you need to be aware of the attainable
bonus points in order to scale the bonus amount appropriately.
Rewarding Agreement¶
Crowdsourcr can automatically award bonuses conditional on agreement between Turkers on each question. This allows one to reward Turkers for good performance in multiple entry tasks.
Two kinds of bonus schemes are available:
linear: a number of bonus points that’s a linear function of the share of other Turkers who gave the same answer to the task. To use this scheme add
<bonus>linear</bonus>to the XML specificationthreshold: an all-or-nothing scheme where the bonus is awarded only if the share of Turkers (including herself) who gave the same answer to the task weakly exceeds a threshold. To use this scheme add
<bonus>threshold:51</bonus>to the XML specification. Note that with simple double data entry (two workers per task) you would want to set the threshold at 51 at least because otherwise every worker receives the bonus (since the share of workers including herself that agrees with her answer is exactly 0.5.)
There are a few rules on how Crowdsourcr determines the level of agreement:
Crowdsourcr assumes that incentivized bonus questions on the same task have the same answer: it will therefore determine agreement among all workers who answered questions on the same task. If you design a survey in a way that on two cHITs you reuse the same task but expect different answers you should either not incentivize them with bonus points, or consider creating two separate tasks.
Crowdsourcr calculates the number of workers who agreed with a specific worker on a question and divides this by the number of workers who could have answered the same question. This makes the implicit assumption that if the worker’s answer is correct then other workers’ answers have to be wrong. An exception is the case where the conditions for reaching a question only involve
aprioripermissableresponses (either on task conditions or question conditions or both): in this case the denominator is the set of all workers who satisfied the same conditions (and hence saw the question).
For example, in the elaborate_conditional_tasks.xml survey the worker answers questions on either red light or blue
light after choosing one of them. Both color choices are aprioripermissable which implies that agreement on the red (blue)
light tasks is only determined among the users who picked red (blue).
Isomorphic Tasks and Modules¶
You sometimes want to run tasks which are essentially identical except for question ordering. This poses a problem for calculating bonuses because Crowdsourcr has no prior knowledge which tasks should be treated as essentially identical.
For that purpose, you can specify a task to be isomorphic to another task. Such an example is provided
in questions_bonus_random_order.xml:
<tasks>
<task>
<content>numbers.html</content>
<taskid>1</taskid>
<modules>numbers</modules>
</task>
<task>
<content>numbers.html</content>
<taskid>2</taskid>
<modules>numbersreverse</modules>
<isomorphictask>1</isomorphictask>
</task>
</tasks>
In this example task 2 is isomorphic to task 1. Crowdsourcr is smart enough to figure out any transitive relationships. For example, if task 3 is isomorphic to 2 and 2 is isomorphic to 1 then all three tasks are isomorphic to each other.
However, the above XML code is incomplete unless you also define the constitutent modules to be isomorphic to each other. In the above example, each task has a single module:
<modules>
<module>
<header>Numbers</header>
<name>numbers</name>
<questions>
(..)
</questions>
</module>
<module>
<header>Numbers</header>
<name>numbersreverse</name>
<isomorphicmodule>numbers</isomorphicmodule>
<questions>
(..)
</questions>
</module>
</modules>
The two modules numbers and numbersreverse are isomorphic and contain the same questions except that they appear in reverse
order in the latter module.
cHIT Validation and Automatic Reassignments¶
Some cHITs require training that not all workers might pass. This poses a problem because (a) you are left with incomplete data and (b) if you use bonuses and double data entry you might inadvertently underpay matched workers who completed the same tasks as the worker who did not pass validation.
You can avoid underpayments by marking training questions as aprioripermissable. This will ensure that workers are only compared to the set of workers who pass validation.
However, this does not address the incomplete data problem. Moreover, you might now overpay workers with threshold bonuses who pass validation because they are now compared only to a single worker (themselves).
In order to address this problem you can attach a validation condition to any cHIT. If the validation condition is not satisfied you can specify a certain number of retries
(default is 0) and create replacement assignments. In order to discourage bots these replacement assignments are created with delay. This delay is set in the cHIT admin panel
(default is 600 seconds).
An example for validated cHITs is provided in questions_with_validation.xml:
<hit>
<hitid>1</hitid>
<tasks>1 2</tasks>
<taskconditions>
<taskcondition>
<taskid>2</taskid>
<condition>
<![CDATA[
1*numbers*number1==22
]]>
</condition>
</taskcondition>
</taskconditions>
<validsubmission>
<condition>
<![CDATA[
1*numbers*number1==22
]]>
</condition>
<invalidRetries>
3
</invalidRetries>
</validsubmission>
</hit>
Validation is enclosed in the validSubmission tag. The condition property specifies a valid submission (using the same syntax as task conditions). The invalidRetries
property specifies the maximum number of replacement assignments that are created after invalid submissions.
Invalid submissions do not receive a bonus (even if you specify bonus points). Invalid submissions are also not included in the main datafile but as a separate file contained within the downloaded zip file.